Using Slack to optimize manual entity resolution
Sometimes it can be really hard to tell whether two things are actually one thing. Is ABC Co. the same thing as ABC Company? How about CBR Construction and Construction CBR Inc.? AAD International and Aerial Automated Defense International? Sometimes you just have to make a judgment call. Easy enough, but now try making thousands of judgment calls per day. Sounds like a job for a computer. Where a computer falls short, however, is when you get examples like the AAD one; there’s just enough similarity for a computer to flag as a possible match, but not quite enough similarity to deal with it automatically. This is where the occasional judgment call becomes useful when used in combination with automated matching.
I work at MaRS Discovery District in Toronto, and to create our analytics products, we pull in data about Canadian ventures from a whole pile of different datasources. My team then analyzes that data to get a comprehensive picture of the Canadian venture ecosystem. The issue with our data is that ventures go by many names, and there is no great way to easily and automatically match ventures from one datasource with another.
Take for example a fake venture that exists in multiple datasources under different names. In Datasource 1, it’s called ‘Cletus Potatoes’. In Datasource 2, it’s called ‘Cletus’ Potatoes Inc.’. In Datasource 3, it’s called ‘Potatopocalypse’ (actually the name of one of their products, being used in place of the business name). In our database, the name is just ‘Cletus Potatoes’.
We can match the venture from Datasource 1 with the venture in our database with a fair amount of confidence, since the string is an exact match (Cletus Potatoes = Cletus Potatoes). The venture in Datasource 2 has the suffix ‘Inc.’ Okay, we can easily enough remove common stopwords like ‘Inc.’ and ‘Incorporated’ when we do our matching, so that Cletus Potatoes = Cletus Potatoes Inc. However, the venture name from Datasource 3 doesn’t even resemble the name in our DB, so we’ll have rely completely on metadata to make that match, and chances are that we’ll have to manually review that match to make sure it’s right (maybe there’s a rough match with the Datasource 3 URL being www.cletuspots.com/potatopocalypse and our DB URL being www.cletuspots.com — enough for these two to be flagged as a possible match).
That venture might be just one in a batch of tens of thousands of companies, and in a batch that big the number of inexact matches requiring manual reviews can easily climb into the thousands. One person (me!) manually reviewing thousands of matches is impossible to do in a reasonable timeline, and unfortunately, it isn’t an option for us to be happy with an almost accurate venture matching. Some ventures have a disproportionate impact on the venture ecosystem, and if we miss a match for a big player, then we could end up multiplying their impact by treating them as multiple companies when they should be treated as one. So, these matches must be reviewed.
Now how do we solve the problem of needing highly accurate matches but me not having the time to manually review them all to ensure high accuracy?
AI?
While a nice AI would be a great way to tackle this problem, in our case this approach is a bit out of scope. It would also be most useful for situations where the names can reasonably be matched with each other using just the names and no other information, but situations like the above where one value is the company’s name and another is the company’s product or service, the sophistication of the AI could grow even further.
So if we can’t use artificial intelligence, that leaves us good old natural intelligence.
Crowdsource it
If I don’t have time to manually review all those companies, then why not get my colleagues to help? Now, I can easily query our DB to review matches, and then execute the right SQL procedures depending on the outcome of my reviews, but there’s no way I can expect all of my colleagues to be able to do the same (and that’s really asking for trouble anyway).
This is where Slack comes in. Slack has a fantastic developer toolkit, and allows you to create custom apps with ‘Home tabs’ that act as interactive user interfaces.
I created a custom Slack app and published venture matches requiring review to the Home tab of the app. So, instead of looking at venture matches in a database table, I can now look at matches in a nice Slack interface:

But more importantly, my colleagues can now review matches right in Slack, too! Each user can have different content published to their home tab, so whenever a user opens the custom Slack app’s Home tab, they are presented with the next review to be done, and can work through them at their own pace.
Conveniently, the URLs are live links, so clicking them will instantly bring the user to a browser where they can research a bit further if needed. Once they’re finished their review, the user just has to click one of the 3 buttons at the bottom to submit their review. Whenever one of the buttons is clicked, the Slack app sends a message to an AWS Lambda function, which then triggers a procedure in our DB that marks the match as verified or refuted, or returns the match to the review queue if the user clicked “Not sure”.
The last question then is how to get people to actually review matches?
Gamify it
If there’s one thing data nerds like to see, it’s numbers. To motivate my colleagues to participate, I built a scoreboard tab where all my colleagues are ranked, along with their scores. Now I can put their competitive personalities to good use.
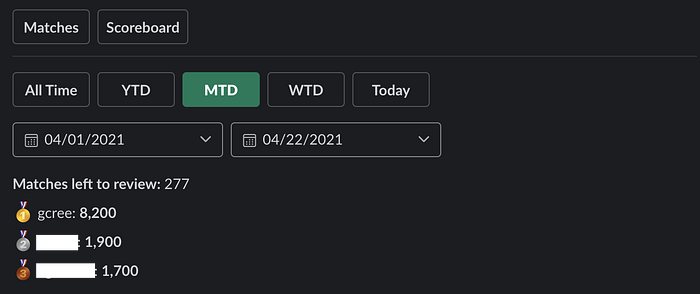
I also programmed a date range feature so that we can see scores from just date X to date Y, which is helpful for holding tournaments. This is because my all-time score is tragically impossible to beat at this point, so everyone gets to start with the same score in tournaments that start and end on a certain date.
There are tons ways I could improve this process (eg, multiple reviews for each match, citations for matches), but this represents a huge improvement over the old method. So far we’ve collectively reviewed over 2,000 matches, which would’ve taken me weeks of dedicated full-time work to do myself. This way, I can review matches when I’m out on a walk, or between meetings, and so can my entire team.
That’s it! I plan to publish an article soon detailing the architecture of this solution for anyone interested in the backend design (it’s built with AWS, Slack, the Serverless Framework, Python, and Postgres).
EDIT: Here’s the architecture article.